Vernetzte kleine LLMs: Die effizientere Alternative zu großen universellen LLMs wie GPT4

Ein Artikel über die Möglichkeiten und Grenzen von LLMs in verschiedenen Anwendungsbereichen.
Einleitung
LLMs, oder Language Learning Models, sind künstliche neuronale Netze, die darauf trainiert sind, natürliche Sprache zu verstehen und zu erzeugen. Sie haben in den letzten Jahren enorme Fortschritte gemacht und können eine Vielzahl von Aufgaben erfüllen, wie z.B. Texte übersetzen, zusammenfassen, generieren, analysieren, klassifizieren, beantworten und vieles mehr. Dabei gibt es zwei grundlegende Arten von LLMs: große universelle LLMs, die auf riesigen Datenmengen trainiert werden und eine hohe Rechenleistung erfordern, und kleine vernetzte LLMs, die auf spezifischen Domänen oder Aufgaben trainiert werden und lokal auf Geräten mit geringer Rechenleistung ausgeführt werden können. In diesem Essay werden die Vor- und Nachteile beider Ansätze diskutiert und die Frage untersucht, wie ein Netzwerk mit kleinen LLMs die Probleme großer LLMs lösen können.
Große universelle LLMs
Große universelle LLMs sind Modelle, die darauf abzielen, eine umfassende und generelle Fähigkeit zur Sprachverarbeitung zu erlangen. Sie werden auf riesigen Textkorpora trainiert, die aus verschiedenen Quellen und Genres stammen, und können daher eine breite Palette von Sprachaufgaben erfüllen. Beispiele für solche Modelle sind GPT-4, Gemini, Claude3 und andere.
Vorteile großer universeller LLMs
Große universelle LLMs haben einige Vorteile, wie z.B. Genauigkeit und Konsistenz, Anpassungsfähigkeit und Wissensdomänen.
Genauigkeit und Konsistenz
Große universelle LLMs können hohe Genauigkeit und Konsistenz bei der Sprachverarbeitung erreichen, da sie von einer großen Menge an Daten lernen. Dies ermöglicht ihnen, die Feinheiten und Nuancen der Sprache zu erfassen und zu berücksichtigen.
Anpassungsfähigkeit von großen LLMs
Sie können flexibel und anpassungsfähig sein, da sie auf verschiedene Anfragen und Kontexte reagieren können. Sie können sich an verschiedene Sprachstile, Genres, Register und Zwecke anpassen und die Erwartungen und Bedürfnisse der Benutzer erfüllen.
Wissensdomänen und Sprachstile
Große LLMs können neue Wissensdomänen und Sprachstile erfassen, indem sie aus dem Internet oder anderen Quellen lernen. Sie können sich ständig weiterentwickeln und aktualisieren, um mit den Veränderungen und Trends in der Sprache und im Wissen Schritt zu halten. Die internen Kapazitäten sind dabei groß genug, um komplexe Strukturen zu lernen und wiederzugegeben.
Nachteile großer universeller LLMs
Allerdings haben große universelle LLMs auch einige Nachteile, wie z.B. Rechenleistung, Transparenz und Ethik.
Rechenleistung und Speicherplatz großer LLMs
Sie erfordern eine enorme Rechenleistung und Speicherplatz, um trainiert und ausgeführt zu werden. Dies bedeutet, dass sie oft auf großen Servern mit GPU-Unterstützung laufen müssen, die teuer und energieintensiv sind. Dies schränkt die Verfügbarkeit und Zugänglichkeit dieser Modelle für viele Benutzer und Geräte ein.
Transparenz
Große LLMs sind oft nicht transparent oder erklärbar, da sie aus Millionen oder Milliarden von Parametern bestehen, die schwer zu interpretieren sind. Dies erschwert es, die Logik und die Gründe für die Entscheidungen und Ergebnisse dieser Modelle zu verstehen und zu überprüfen.
Fragen der Ethik und Manipulation
Ethische und soziale Probleme können zwar nicht nur durch große LLMs verursacht werden, wie z.B. Bias, Diskriminierung, Manipulation, Plagiat, Datenschutzverletzung und andere, sie sind aufgrund der Datenmenge jedoch besonders anfällig dafür. Die enormen Datenmengen können dabei auch aus unkontrollierten oder unzuverlässigen Datenquellen stammen. Dies kann zu unerwünschten oder schädlichen Auswirkungen für die Benutzer und die Gesellschaft führen.
Kleine vernetzte LLMs
Kleine vernetzte LLMs sind Modelle, die darauf abzielen, eine spezifische und begrenzte Fähigkeit zur Sprachverarbeitung zu erlangen. Sie werden auf bestimmten Domänen oder Aufgaben trainiert, die für den Benutzer oder das Gerät relevant sind, und können lokal auf Geräten mit geringer Rechenleistung ausgeführt werden. Beispiele für solche Modelle sind Llama, Mistral-7b, phi-2 und andere.
Vorteile kleiner vernetzter LLMs
Kleine vernetzte LLMs haben einige Vorteile, wie z.B. Effizienz und Geschwindigkeit, Anpassung an die Aufgabe und Datensicherheit.
Effizienz und Geschwindigkeit
Kleine LLMs können eine hohe Effizienz und Geschwindigkeit bei der Sprachverarbeitung erreichen, da sie nur die notwendigen Daten und Parameter verwenden. Dies ermöglicht ihnen, die Sprache schneller und genauer zu verarbeiten und zu erzeugen.
Spezialisierung kleiner LLMs auf eine Aufgabe
Sie können maßgeschneidert und personalisiert sein, da sie auf die Bedürfnisse und Präferenzen des Benutzers oder des Geräts zugeschnitten werden können. Sie können die Sprache an die spezifische Domäne oder Aufgabe anpassen und die Relevanz und Qualität der Ergebnisse verbessern.
Datensicherheit
Sie können sicherer und vertrauenswürdiger sein, da sie lokal ausgeführt werden und keine sensiblen Daten oder Ressourcen an externe Server senden müssen. Dies schützt die Privatsphäre und die Sicherheit der Benutzer und der Geräte.
Nachteile kleiner vernetzter LLMs
Allerdings haben kleine vernetzte LLMs auch einige Nachteile, wie z.B. Genauigkeit, Flexibilität und Aktualität.
Genauigkeit und Konsistenz kleiner LLMs
Sie können eine geringere Genauigkeit und Konsistenz bei der Sprachverarbeitung haben, da sie von einer begrenzten Menge an Daten lernen. Dies kann dazu führen, dass sie die Sprache unvollständig oder falsch verstehen oder erzeugen.
Flexibilität
Kleine LLMs können unflexibel und unfähig sein, da sie nicht auf verschiedene Anfragen und Kontexte reagieren können. Sie können sich nicht an verschiedene Sprachstile, Genres, Register und Zwecke anpassen und die Erwartungen und Bedürfnisse der Benutzer erfüllen.
Aktualität kleiner LLMs
Sie können veraltet oder irrelevant werden, da sie nicht aus neuen Wissensdomänen oder Sprachstilen trainiert worden sind. Das Training kleiner LLMs und deren Spezialisierung auf eine Aufgabe (Finetuning), erfordert eine hohe Präzision der Trainingsdaten. Auch wenn das Training mit kleinerer Hardware durchgeführt werden kann, so ist Spezialwissen und Zeit erforderlich.
Wie ein Netzwerk mit kleinen LLMs die Probleme großer LLMs lösen können
Eine mögliche Lösung für die Probleme großer LLMs ist, ein Netzwerk mit kleinen LLMs zu erstellen, dass die Vorteile beider Ansätze kombiniert. Ein solches Netzwerk könnte aus mehreren kleinen LLMs bestehen, die jeweils eine spezifische Domäne oder Aufgabe abdecken, wie z.B. Coding, Texte erstellen, Bilder interpretieren etc. Diese kleinen LLMs könnten miteinander kommunizieren und kooperieren, um komplexe und vielfältige Sprachaufgaben zu erfüllen.
Vorteile eines Netzwerks kleiner LLM
Ein solches Netzwerk könnte eine Reihe von Vorteilen bieten:
- Es könnte eine hohe Genauigkeit und Konsistenz in der Sprachverarbeitung erreichen, indem es die Expertise und das Wissen der einzelnen kleinen LLMs nutzt. Dies würde ein umfassendes und korrektes Verstehen und Erzeugen von Sprache ermöglichen.
- Es könnte flexibel und anpassungsfähig sein, indem es die Anfragen und den Kontext des Benutzers oder des Geräts berücksichtigt und die geeigneten kleinen LLMs auswählt oder kombiniert. Es könnte sich an verschiedene Sprachstile, Genres, Register und Zwecke anpassen und die Erwartungen und Bedürfnisse der Benutzer erfüllen.
- Es könnte neue Wissensgebiete und Sprachstile abdecken, indem es die kleinen LLMs ständig aktualisiert oder erweitert. Dies würde eine ständige Weiterentwicklung und Aktualisierung ermöglichen, um mit den Veränderungen und Trends in Sprache und Wissen Schritt zu halten.
Herausforderungen eines Netzwerks für kleine LLM
Ein solches Netzwerk könnte jedoch auch einige Herausforderungen mit sich bringen:
- Es könnte sehr komplex und schwierig sein, das Netzwerk aufzubauen und zu verwalten, da es viele kleine LLMs koordinieren und integrieren muss. Dies würde voraussetzen, dass die kleinen LLMs kompatibel und synchronisiert sind und dass die Kommunikation und Kooperation zwischen ihnen reibungslos und effektiv verläuft.
- Es könnte zu ethischen und sozialen Problemen führen, wie z.B. Voreingenommenheit, Diskriminierung, Manipulation, Plagiat, Verletzung der Privatsphäre usw., wenn die Daten oder Ergebnisse der kleinen LLMs nicht angemessen kontrolliert oder reguliert werden. Dies setzt voraus, dass kleine LLMs ethische und soziale Standards einhalten und dass die Rechenschaftspflicht und Transparenz des Netzwerks gewährleistet ist.
Eine Frage der Kosten
Lokal durchgeführte LLM haben geringere Anforderungen an die Hardware. Die Hardware ist in der Regel billiger und die Verfügbarkeit auf dem Markt höher. Die Betriebskosten der Hardware sind geringer und der Aufwand für Installation und Wartung geringer als bei größeren Servern. Als Hardware reicht oft ein gut ausgestatteter Gaming-PC (mit guter Grafikkarte, z.B. NVIDIA RTX4090).
Die Kosten für große LLMs werden in Token berechnet. Tokens sind die kleinsten Einheiten, aus denen LLMs die Sprache aufbauen. Dies können Buchstaben, Wörter, Satzzeichen oder andere Symbole sein. Die Anzahl der Tokens, die ein LLM benötigt, um einen Text zu verarbeiten oder zu erzeugen, hängt von der Länge und Komplexität des Textes ab. Tokens sind also Zeichen, und die Anzahl der Tokens für ein Wort errechnet sich dann aus der Anzahl der Zeichen (z.B. Buchstaben).
Beispiel für Kostenberechnung von LLMs
Derzeit kostet beispielsweise die Nutzung von GPT-4, einem der größten universellen LLMs, etwa 0,03 US-Dollar pro 1000 Token (Output).
Die Einleitung besteht aus etwa 227 Token mit 858 Zeichen. Das bedeutet, dass dieser Abschnitt etwa 0,007 $ gekostet hat. Dies scheint auf den ersten Blick nicht viel zu sein, kann sich aber bei komplexen Abfragen schnell auf mehrere Dollar summieren. Kosten fallen sowohl für die Eingabe (Input) als auch für die Ausgabe (Output) an.
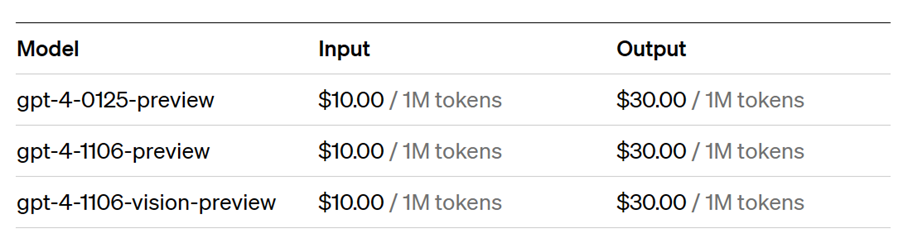
Abbildung 1: Kosten OpenAI GPT4 (Stand 10.03.2024)
Ein kleineres vernetztes LLM könnte weniger Tokens verbrauchen, wenn es auf eine spezifische Domäne oder Aufgabe zugeschnitten ist, und somit die Kosten senken. Allerdings könnte die Ausführung oder Synchronisation von vielen kleinen LLMs die Kosten wieder erhöhen, wenn sie mehr Ressourcen benötigen.
Fazit
LLMs sind künstliche neuronale Netze, die natürliche Sprache verstehen und produzieren können. Es gibt zwei Grundtypen: große, universelle LLMs, die auf großen Datenmengen trainiert werden und eine hohe Rechenleistung benötigen, und kleine, vernetzte LLMs, die auf spezifischen Domänen oder Aufgaben trainiert werden und lokal auf Geräten mit geringer Rechenleistung ausgeführt werden können. Beide Ansätze haben Vor- und Nachteile, die in diesem Artikel diskutiert werden. Eine mögliche Lösung für die Probleme großer LLMs besteht darin, ein Netzwerk kleiner LLMs zu schaffen, das die Vorteile beider Ansätze kombiniert. Ein solches Netzwerk könnte einige Vorteile, aber auch einige Herausforderungen mit sich bringen. Die Zukunft der LLM hängt davon ab, wie Forscher und Entwickler diese Möglichkeiten und Grenzen berücksichtigen und wie Nutzer und Gesellschaft diese Technologien nutzen und regulieren.
Wir laden Sie ein, sich an der Diskussion zu beteiligen. Teilen Sie Ihre Gedanken und Erfahrungen in den Kommentaren und in sozialen Netzwerken. Ihre Meinung ist wichtig, um die Zukunft dieser innovativen Technologie mitzugestalten. Lassen Sie uns gemeinsam die Möglichkeiten erkunden und nutzen!