
Teil 3 – Projektmaker – KI Objekterkennung in Bildern mit .Net
2. Einführung in VOTT (Visual Object Tagging Tool)
Warum man Objekte in Bildern tagt und wie es mit VOTT schnell und unkompliziert geht.
Kurze Erklärung zum Tagging
Die Markierung (Tagging) von Objekten in Bildern ist für das Training von Modellen der künstlichen Intelligenz und des maschinellen Lernens unerlässlich, da sie den Algorithmen hilft, Muster und Merkmale zu erkennen. Tags dienen als Annotationen, die den Algorithmen erklären, was sich in einem bestimmten Bereich des Bildes befindet. Auf diese Weise lernt das Modell, ähnliche Objekte in neuen, ungesehenen Daten zu identifizieren. Ohne diese annotierten Daten hätte das Modell Schwierigkeiten, den Kontext oder die Bedeutung der Pixel in einem Bild zu verstehen. Kurz gesagt, die Markierung erleichtert es der KI, auf der Grundlage der gelernten Muster sinnvolle Analysen und Vorhersagen zu treffen.
Anwendung von VOTT zur Erstellung von Datensätzen für KI-Modelle in der Objekterkennung
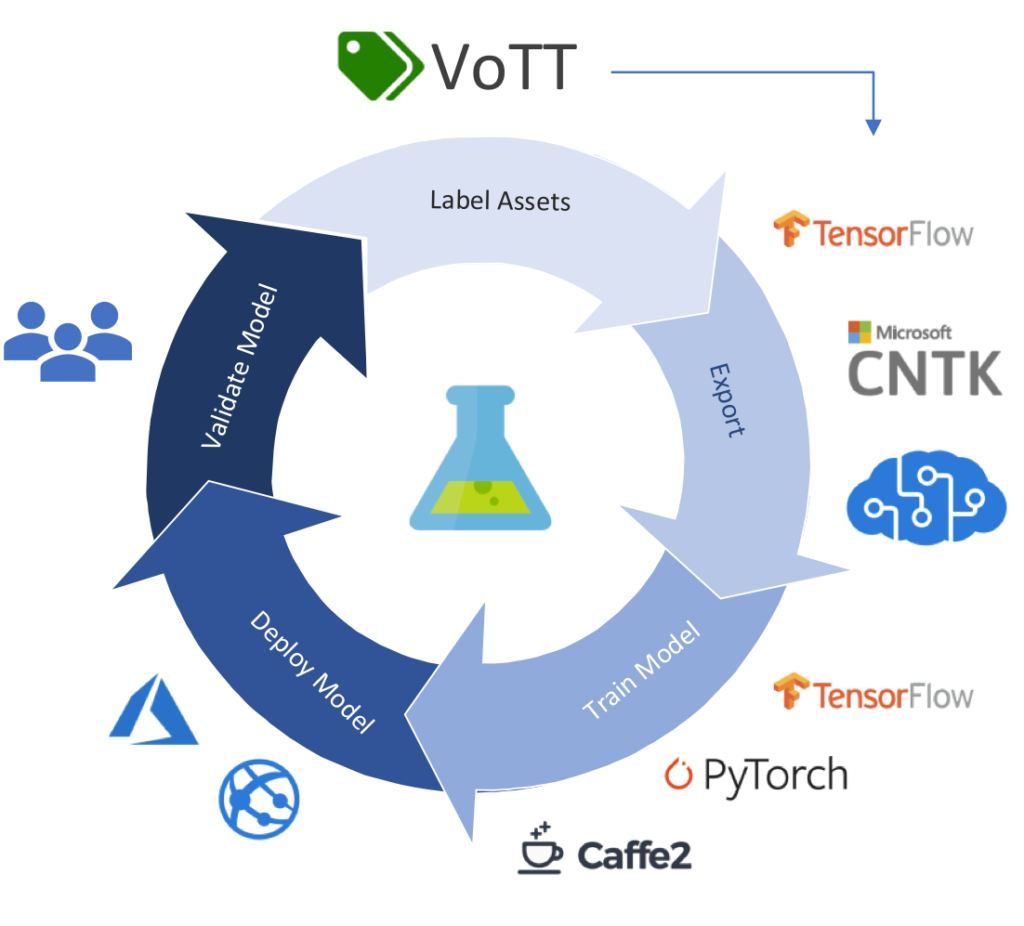
Die Erstellung eines qualitativ hochwertigen Datensatzes ist entscheidend für das Training effizienter KI-Modelle in der Objekterkennung. Eines der nützlichen Tools für diesen Prozess ist Microsofts “Visual Object Tagging Tool” (VOTT).
Kurzanleitung
Schritt 1: Vorbereitung und Installation
- Laden Sie VOTT von der GitHub-Seite herunter und installieren Sie es.
- Starten Sie das Tool und melden Sie sich mit Ihrem Microsoft-Konto an, wenn erforderlich.
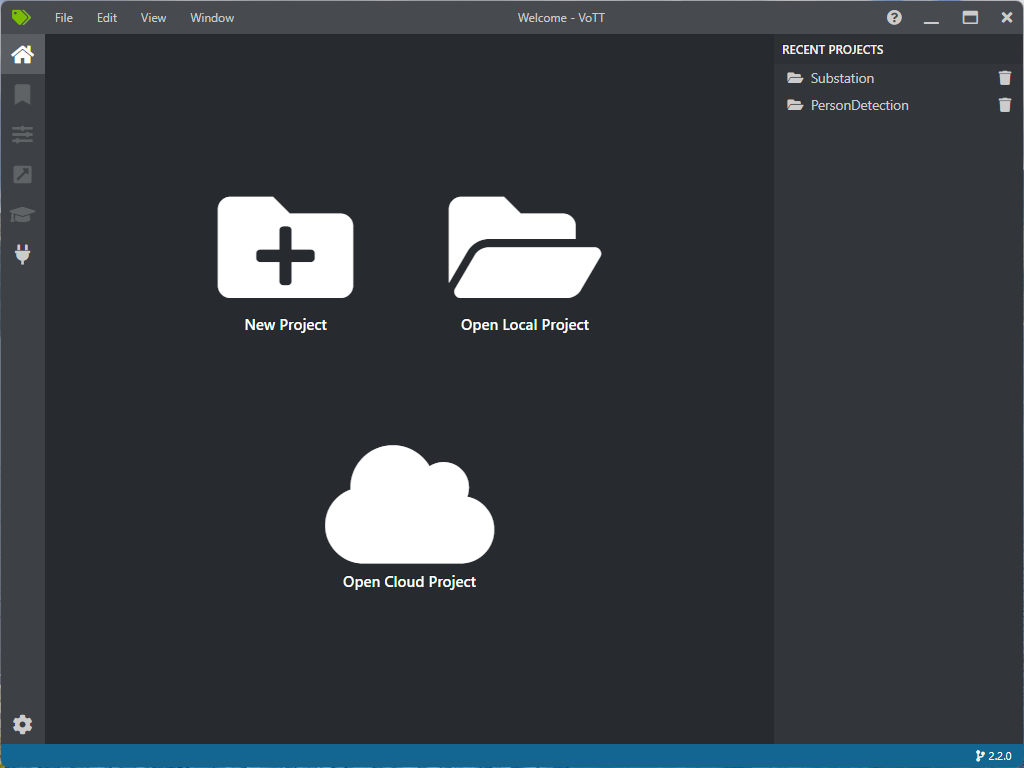
Schritt 2: Projekt Erstellung
1. Klicken Sie auf “New Project”.
- Benennen Sie das Projekt und wählen Sie den Speicherort für die Projektdateien aus.
- Stellen Sie sicher, dass Sie “Object Detection” als Projekttyp auswählen.
Schritt 3: Konfiguration der Quelle und des Zielverzeichnisses
- Fügen Sie den Pfad zum Ordner mit Ihren Bildern in das Feld “Source Connection” ein. Bei der ersten Verwendung müssen Sie “Add Connection ” wählen.

- Geben Sie einen Wert bei “Display Namen” ein (frei wählbar).
- Bei Provider wählen Sie “Local File System” aus.
- Mit “Select Folder” wählen Sie den Ordner mit den Bilder aus.

- Wählen Sie ein “Target Connection” Verzeichnis für die annotierten Dateien.
- Wählen sie den gleichen Eintrag wie bei “Source Connection” aus.
- Bestätigen Sie mit “Save Project”
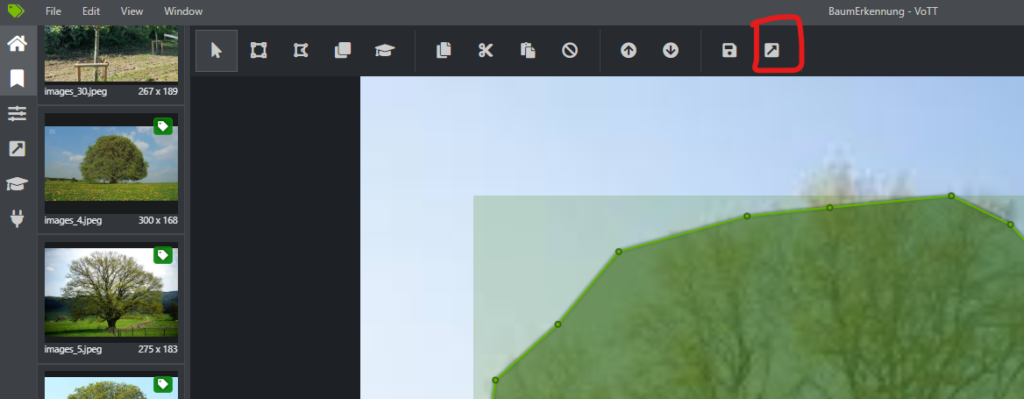
Schritt 4: Tag-Erstellung und Annotation
- Klicken Sie auf den “+ Tag” Button, um neue Tags zu erstellen.
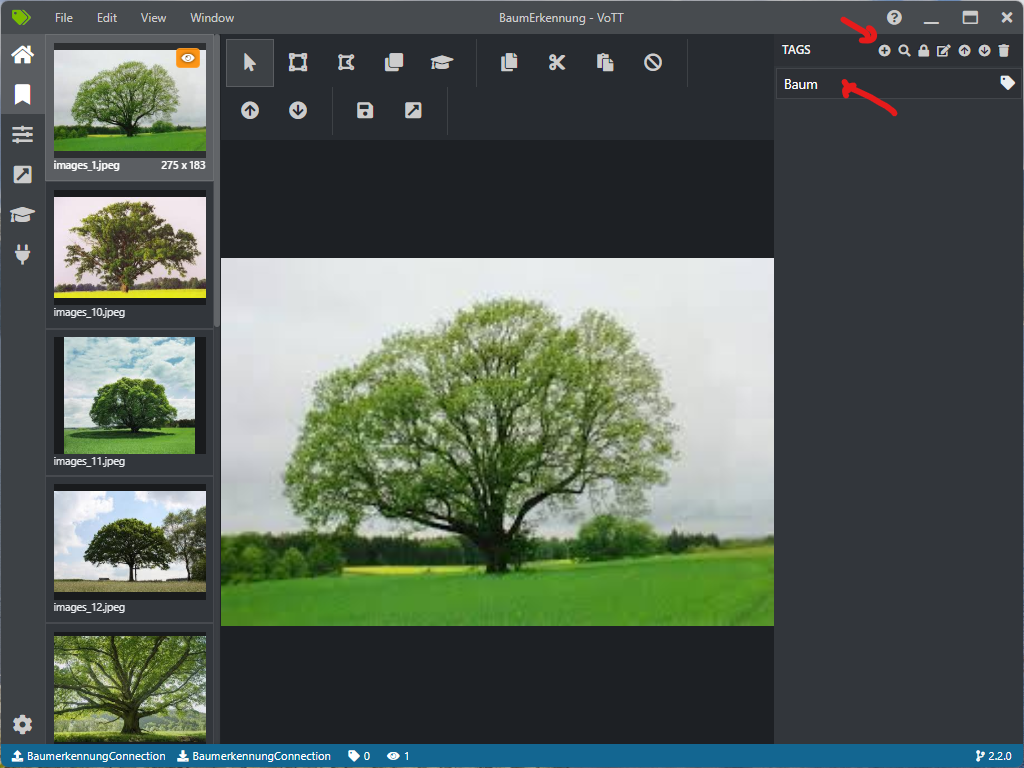
- Markieren Sie auf jedem Bild das zu erkennende Objekt
- Navigieren Sie zu den Bildern und markieren Sie die Objekte mit den zuvor erstellten Tags.
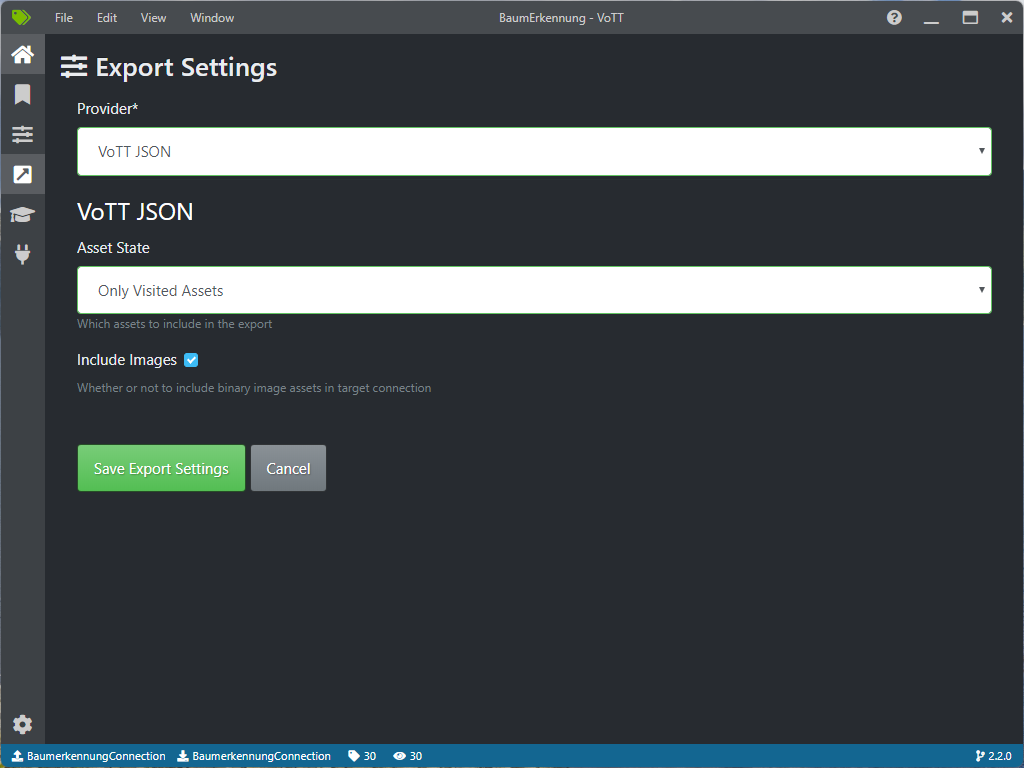
Schritt 5: Datensatz Exportieren
- Sobald alle Bilder annotiert sind, klicken Sie auf “Export” und wählen Sie das gewünschte Format (JSON).
- Überprüfen Sie den Datensatz, um sicherzustellen, dass alle Annotationen korrekt sind.
Schritt 6: Datensatz für KI-Training Verwenden
- Verwenden Sie den exportierten Datensatz als Trainingsdaten für Ihre Objekterkennungsmodelle in Frameworks wie dem .Net Model Builder, TensorFlow oder PyTorch.
Vorteile der Verwendung von VOTT
- Einfache Benutzeroberfläche
- Multi-Plattform-Kompatibilität
- Unterstützung für verschiedene Exportformate
Eine Ausführliche Anleitung wird auf GitHub bereitgestellt.
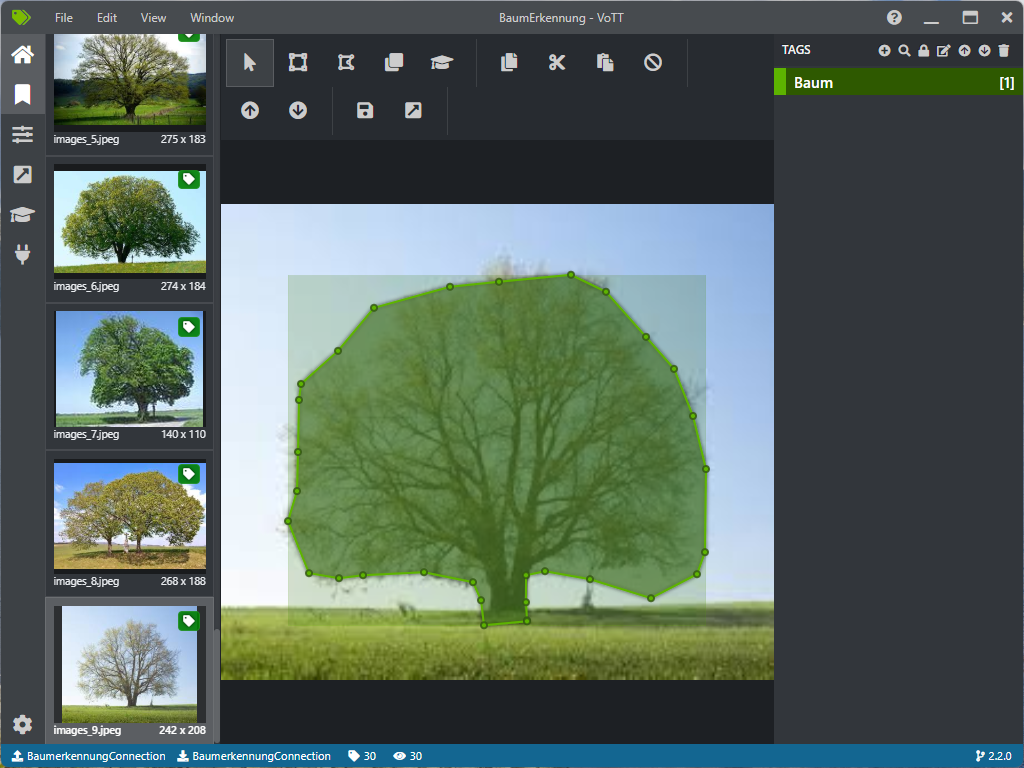
Erstellen Sie jetzt einen Datensatz und speichern Sie diesen ab. Für einen Test können Sie z.B. Bilder aus der Google-Bildersuche verwenden. In unserem Beispiel möchten wir Bäume auf einem Bild erkennen.
Für das Projekt wurde ein Datensatz von 30 Bilder erstellt.
Quellen
Weiter geht es mit Teil 4…
Überblick:
Teil 1 – Teil 2 – Teil 3 – Teil 4 – Teil 5
Das Projekt zum Download auf GitHub.
















4 Antworten
[…] 1 – Teil 2 – Teil 3 – Teil 4 – Teil […]
[…] Weiter geht es mit Teil 3… […]
[…] 1 – Teil 2 – Teil 3 – Teil 4 – Teil […]
[…] 1 – Teil 2 – Teil 3 – Teil 4 – Teil […]