
EMO – So realistisch und doch virtuell: Die Revolution der sprechenden Köpfe durch Diffusionsmodelle

Im Zeitalter von virtueller Realität und künstlicher Intelligenz ist die Erzeugung lebensechter sprechender Gesichter, die in Echtzeit auf Audioeingaben reagieren, eine beeindruckende technologische Errungenschaft. Ein herausragendes Beispiel für diese innovative Entwicklung ist das EMO-Modell, ein fortschrittliches Framework zur Generierung ausdrucksstarker Porträtvideos auf der Basis von Diffusionsmodellen. Diese bahnbrechende Methode ermöglicht es, aus einem einzigen Referenzbild und einem zugehörigen Audioclip, wie Sprache oder Gesang, überzeugende Avatar-Videos mit ausdrucksstarken Gesichtsausdrücken und vielfältigen Kopfpositionen zu erzeugen. EMO zeichnet sich dabei durch die Fähigkeit aus, Videos beliebiger Länge in Abhängigkeit von der Dauer des Eingabeaudios zu generieren, was in der aktuellen Forschung und Entwicklung einzigartig ist.
Ziel und Innovationen von EMO
![Quelle: EMO: Emote Portrait Alive - Generating
Expressive Portrait Videos with Audio2Video
Diffusion Model under Weak Conditions [https://arxiv.org/pdf/2402.17485.pdf]](https://www.techzeitgeist.de/wp-content/uploads/2024/03/image.png)
Das primäre Ziel von EMO ist es, die Realitätstreue und den Ausdruck von sprechenden Kopf-Videos zu verbessern. Hierbei liegt der Fokus auf der dynamischen und nuancierten Beziehung zwischen Audiohinweisen und Gesichtsbewegungen. EMO nutzt ein direktes Audio-zu-Video-Syntheseverfahren, das die Notwendigkeit von Zwischenmodellen oder Gesichtslandmarken umgeht, um nahtlose Frame-Übergänge und konsistente Identitätserhaltung im gesamten Video zu gewährleisten.
Vorteile von Diffusionsmodellen
Die Identität des Charakters in den generierten Videorahmen wird durch spezielle Mechanismen erhalten, die sicherstellen, dass die visuellen Merkmale des Avatars konsistent bleiben. Um die Stabilität während des Generierungsprozesses zu verbessern, werden zwei Kontrollmechanismen verwendet: ein Mechanismus zur Kontrolle der Bewegungsgeschwindigkeit und ein anderer zur Steuerung der Gesichtsausdrücke.
Die Verwendung von Diffusionsmodellen für die Erzeugung von sprechenden Köpfen bietet mehrere Vorteile. Diese Modelle sind bekannt für ihre Fähigkeit, hochqualitative Bilder zu produzieren, indem sie auf großen Bild-Datensätzen trainiert werden und einen progressiven Generierungsansatz verfolgen. Dies ermöglicht die Erstellung von Bildern mit beispielloser Detailgenauigkeit und Realismus.
Stabilität und Kontrolle
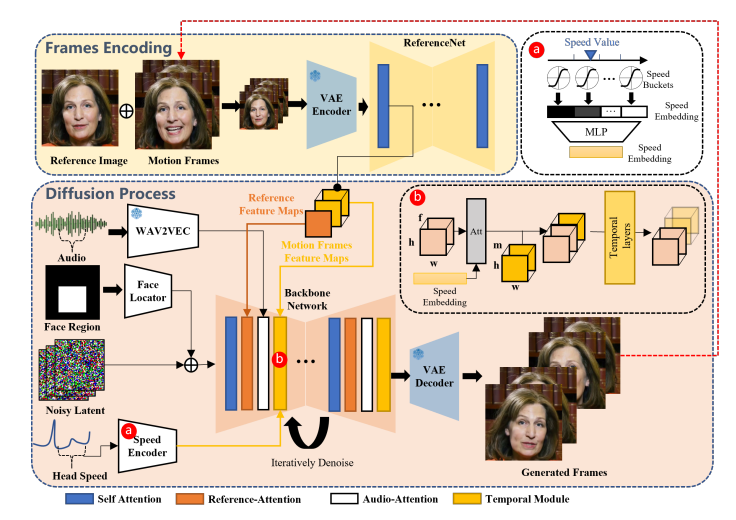
Um die Stabilität während des Generierungsprozesses zu verbessern, verwendet EMO zwei Kontrollmechanismen: einen Geschwindigkeitsregler und einen Gesichtsregionen-Controller. Diese fungieren als Hyperparameter und bieten subtile Steuersignale, die die Vielfalt und den Ausdruck der endgültigen generierten Videos nicht beeinträchtigen.
Geschwindigkeits- und Identitätserhaltung
EMO kodiert die Geschwindigkeit der Kopfdrehung in Geschwindigkeitsschichten und erhält die Identität des Charakters in den generierten Videoframes, indem es Referenzmerkmale aus dem Referenzbild extrahiert und mit den latenten Merkmalen verschmilzt. Dies gewährleistet, dass der Charakter im generierten Video mit dem Eingabereferenzbild übereinstimmt.
Qualitätsbewertung und -erhaltung
Referenzmerkmale werden aus dem Referenzbild extrahiert und mit den latenten Merkmalen verschmolzen, um die Identität und den Ausdruck des Charakters beizubehalten. Zeitliche Module und spezielle Aufmerksamkeitsschichten werden in die Hintergrundnetzwerke integriert, um die zeitlichen Beziehungen zwischen den Videorahmen zu erfassen und die Lippen-Synchronisation zu verbessern.
Zur Bewertung der Qualität und des Ausdrucks der generierten Videos verwendet EMO verschiedene Metriken, darunter FID (Fréchet Inception Distance), SyncNet für die Lippen-Synchronisation und E-FID für die Gesichtsausdrucksparameter. Diese umfassenden Bewertungsmethoden stellen sicher, dass die generierten Videos nicht nur realistisch, sondern auch ausdrucksstark sind.
Fazit
EMO repräsentiert einen bedeutenden Fortschritt in der Generierung von sprechenden Kopf-Videos, indem es die Grenzen herkömmlicher Methoden überwindet und eine neue Ära der visuellen Kommunikation einleitet. Mit seiner Fähigkeit, realistische und ausdrucksstarke Videos zu erzeugen, die auf Audioeingaben reagieren, steht EMO an der Spitze der digitalen Innovation, die die Art und Weise, wie wir mit virtuellen Charakteren interagieren, revolutionieren könnte.
Quelle:
Alle Details gibt es hier: 2402.17485.pdf (arxiv.org)
Wir laden Sie ein, sich an der Diskussion zu beteiligen. Teilen Sie Ihre Gedanken und Erfahrungen in den Kommentaren und in sozialen Netzwerken. Ihre Meinung ist wichtig, um die Zukunft dieser innovativen Technologie mitzugestalten. Lassen Sie uns gemeinsam die Möglichkeiten erkunden und nutzen!

















