
DeepSeek v3-0324: Das Open-Source-Sprachmodell der Zukunft?

Die Veröffentlichung von DeepSeek v3-0324 am 24. März 2025 hat in der KI-Community großes Interesse geweckt. Entwickelt wurde das Modell vom chinesischen KI-Labor DeepSeek in Hangzhou, Zhejiang. Es stellt eine bedeutende Weiterentwicklung dar und zählt aktuell zu den leistungsfähigsten Open-Source-Sprachmodellen überhaupt. Besonders überzeugt es in den Bereichen Programmieren, Mathematik und Mehrsprachigkeit. Was macht DeepSeek v3-0324 einzigartig und warum sollte man es genauer betrachten?
Leistungsmerkmale und Architektur
DeepSeek v3-0324 umfasst beeindruckende 685 Milliarden Parameter, nutzt allerdings dank einer innovativen Mixture-of-Experts (MoE)-Architektur nur 37 Milliarden Parameter pro Token. Dies ermöglicht sowohl ressourcenschonendes Arbeiten als auch hohe Verarbeitungsgeschwindigkeiten. Darüber hinaus setzt das Modell auf die bereits bewährte Multi-head Latent Attention (MLA)-Technologie.
Die Trainingsphase erfolgte auf der Grundlage von 14,8 Billionen qualitativ hochwertigen Tokens. Insgesamt benötigte das Training etwa 2,788 Millionen GPU-Stunden (H800), was vergleichsweise geringe Kosten von rund 5,5 Millionen US-Dollar verursachte.
Neben seiner Effizienz punktet das Modell insbesondere durch eine außergewöhnliche Präzision bei der Datenverarbeitung. Die optimierte Feinabstimmung während des Trainings ermöglicht eine zuverlässige Erkennung komplexer Muster und Zusammenhänge.
Technische Eckdaten im Überblick
- Parameter: 685 Milliarden (37 Milliarden aktiviert pro Token)
- Architektur: Mixture-of-Experts, MLA
- Trainingsdaten: 14,8 Billionen Tokens
- Kosten: ca. 5,5 Mio. USD
- Lizenz: MIT
- Hosting: Hugging Face (US)
- GPU-Nutzung: Optimiert und ressourcenschonend
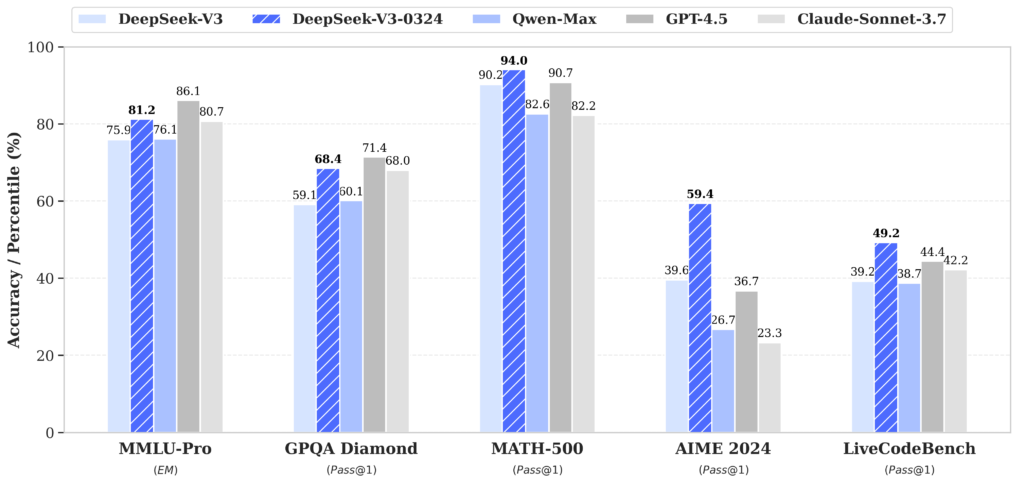
Herausragende Benchmarks
DeepSeek v3-0324 erzielte beeindruckende Resultate im renommierten aider’s Polyglot-Benchmark mit einem Score von 55 %. Dies ist ein erheblicher Fortschritt im Vergleich zur vorherigen Version und bringt das Modell nahe an Top-Konkurrenten wie Claude Sonnet 3.7 sowie spezialisierte Modelle wie R1 und o3-mini heran.
Besonders stark zeigt sich DeepSeek v3-0324 bei:
- Mathematischen Aufgaben: Herausragende Leistung bei komplexen algebraischen und geometrischen Problemen
- Programmieraufgaben: Zuverlässige Generierung umfangreicher Codeabschnitte (bis zu 700 Zeilen ohne Fehler)
- Mehrsprachigkeit: Hohe Effektivität in verschiedenen Sprachen, insbesondere bei Übersetzungen und Sprachverständnis
- Langzeitkontext: Exzellente Performance bei der Verarbeitung längerer Texte und Zusammenhänge
Open-Source: Zugänglichkeit und Flexibilität
Das Modell ist vollständig Open-Source und steht unter der MIT-Lizenz frei zur Verfügung. Dies erleichtert es Forschern, Entwicklern und Unternehmen, das Modell zu nutzen, anzupassen und weiterzuentwickeln, ohne hohe Lizenzkosten tragen zu müssen. Durch die einfache Verfügbarkeit auf Plattformen wie Hugging Face wird der Einstieg sowie die Integration in bestehende Anwendungen zusätzlich erleichtert.
Die offene Struktur des Modells fördert Innovationen, indem Entwickler eigene Modifikationen und Anpassungen unmittelbar am Modell vornehmen können, um spezifische Anforderungen optimal zu erfüllen.
Nutzererfahrung und Community-Feedback
Obwohl die technische Leistung deutlich verbessert wurde, äußert sich ein Teil der Nutzer kritisch bezüglich des Kommunikationsstils des Modells. Dieser werde als zu „intellektuell“ und „roboterhaft“ empfunden – insbesondere verglichen mit der Vorgängerversion. Offensichtlich wurde ein bewusster Fokus auf technische Genauigkeit gesetzt, der die natürliche Ausdrucksweise einschränkt.
Dennoch gibt es auch zahlreiche positive Rückmeldungen, die insbesondere die Zuverlässigkeit und Präzision des Modells hervorheben. Unternehmen mit technisch anspruchsvollen Anforderungen profitieren besonders von der verbesserten Genauigkeit und reduzierten Fehlerquote.
Vergleich mit anderen Modellen
Im Vergleich mit führenden Closed-Source-Modellen schlägt sich DeepSeek v3-0324 bemerkenswert gut. Insbesondere Claude Sonnet 3.5 wird häufig als direkter Wettbewerber betrachtet. Zwar erreicht DeepSeek in spezifischen Benchmarks gleiche oder bessere Ergebnisse, allerdings fehlt ihm teilweise noch die letzte Durchschlagskraft bei besonders tiefgründigen, logischen Aufgabenstellungen.
Hier vermutet die Community, dass bereits an einer spezialisierten Nachfolgeversion, DeepSeek-R2, gearbeitet wird, um genau diese Schwäche zukünftig zu beheben. Bereits jetzt zeigt sich jedoch eine klare Überlegenheit in konkreten Anwendungen, wie der Codegenerierung und mathematischen Unterstützung.
Potenzial für Forschung, Bildung und Praxis
Die Kombination aus hoher Leistung und offener Zugänglichkeit macht DeepSeek v3-0324 besonders attraktiv für Forschungsprojekte sowie praktische Anwendungen in Entwicklung und Industrie. Besonders dort, wo Genauigkeit in Mathematik, Programmierung und Mehrsprachigkeit gefordert sind, stellt das Modell aktuell eine der besten Lösungen dar.
In der Zukunft könnte das Modell zudem eine zunehmende Rolle in Bildung und Wissenschaft spielen. Potenzielle Einsatzgebiete sind die Automatisierung wissenschaftlicher Analysen, Unterstützung in Forschungsprojekten oder das Training und die Ausbildung von Nachwuchskräften.
Fazit
DeepSeek v3-0324 ist ein bedeutender Fortschritt für Open-Source-KI-Technologien. Trotz kleiner Einschränkungen im Gesprächsstil überzeugt das Modell durch beeindruckende technische Eigenschaften. Zukünftige Versionen, wie etwa DeepSeek-R2, könnten bestehende Schwachpunkte überwinden und DeepSeek als festen Bestandteil an der Spitze der KI-Technologien etablieren.
DeepSeek-V3 GitHub Page Contribute to deepseek-ai/DeepSeek-V3 development
DeepSeek V3-0324 on Hugging Face We’re on a journey to advance
DeepSeek V3-0324 Generated 700 Lines of Code without Breaking
DeepSeek V3-0324 New DeepSeek model released Data Science
Hinweis: Der Artikel wurde mit Unterstützung von KI erstellt.

















